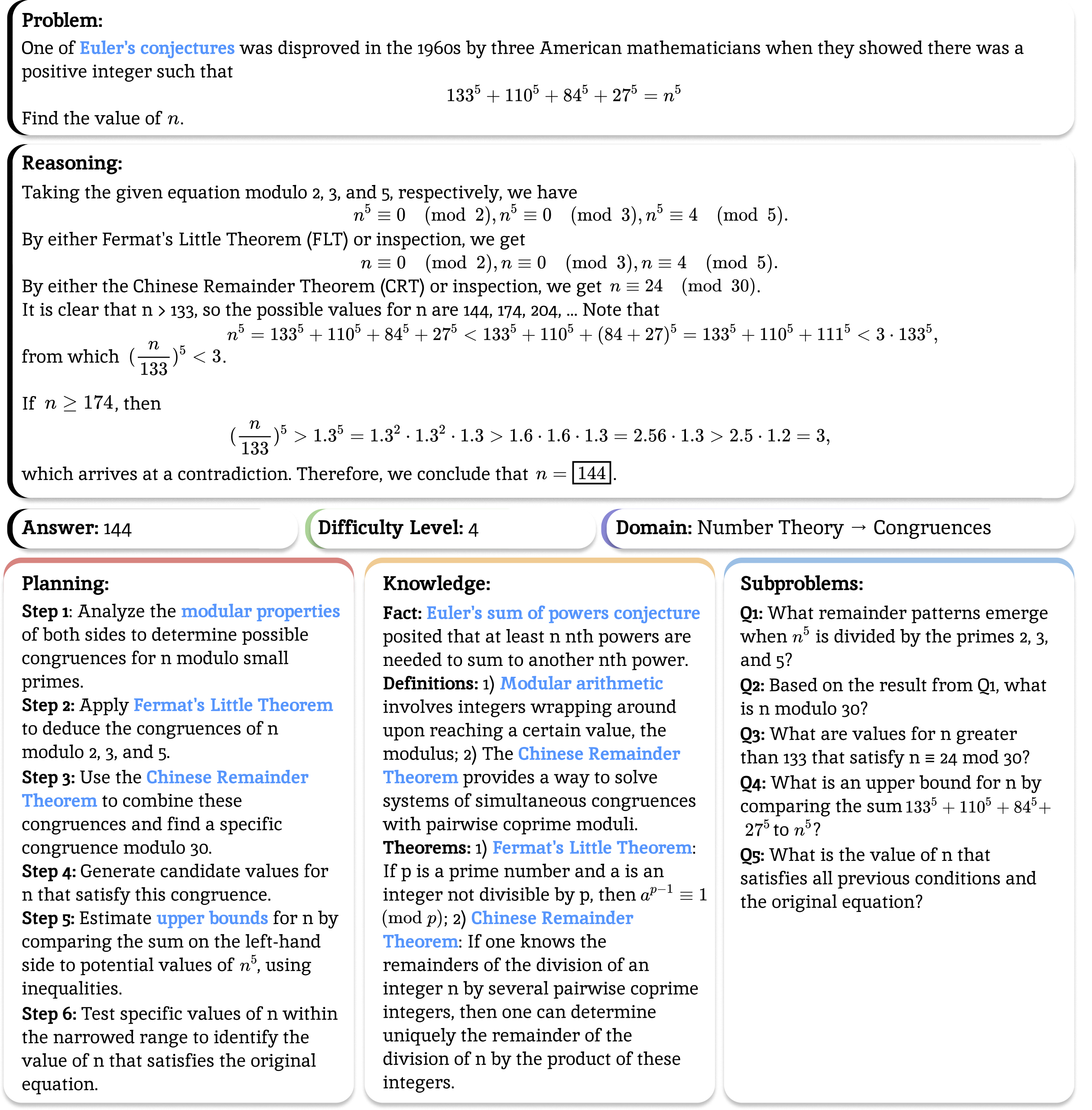
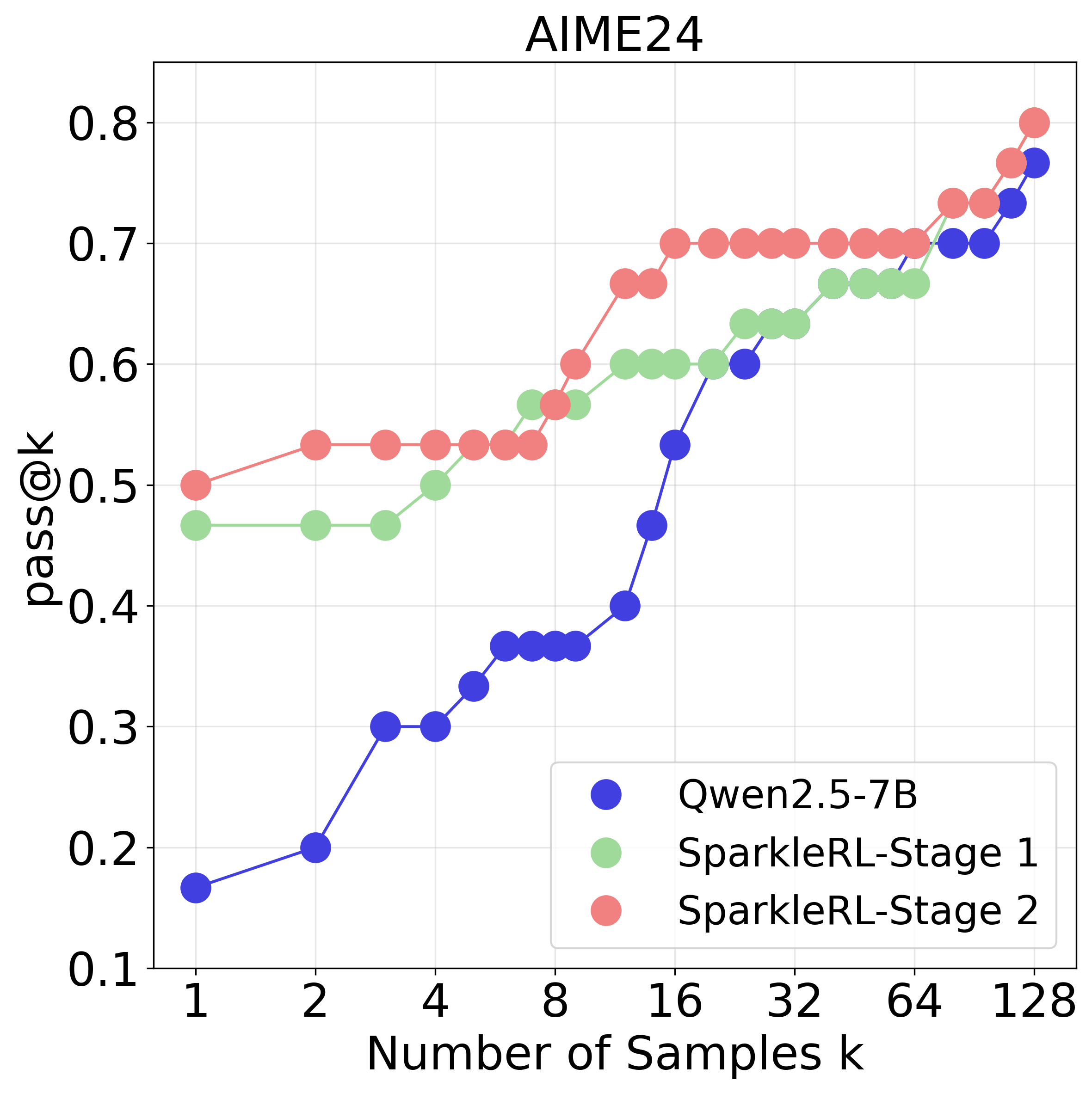
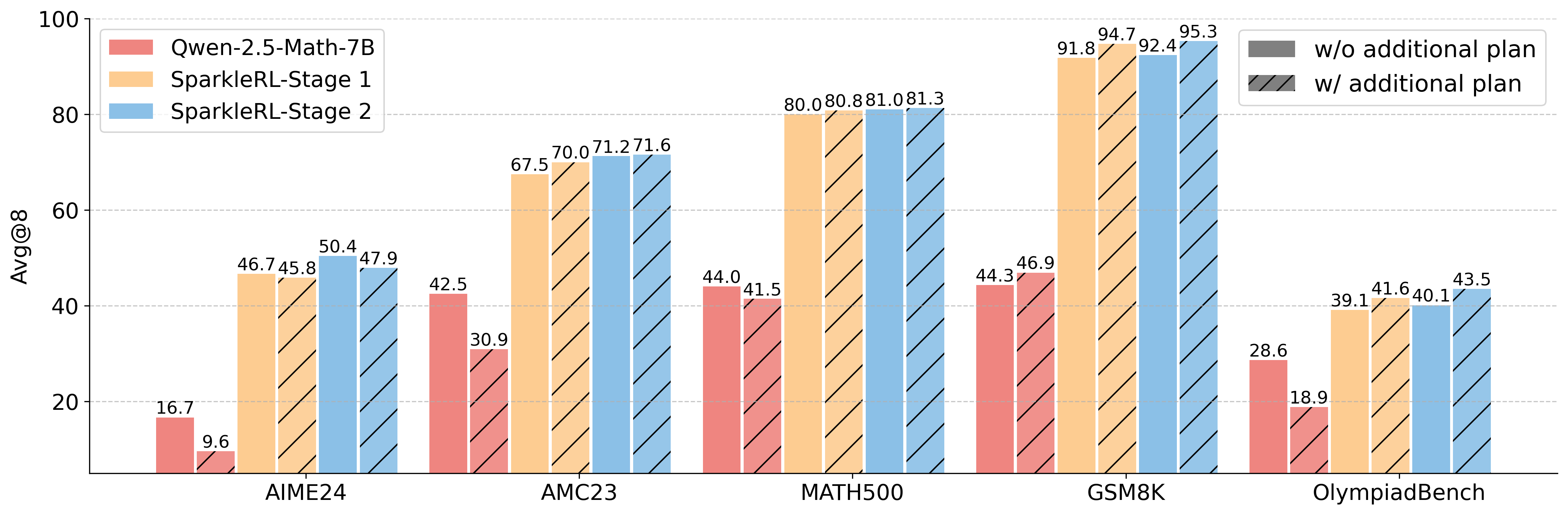
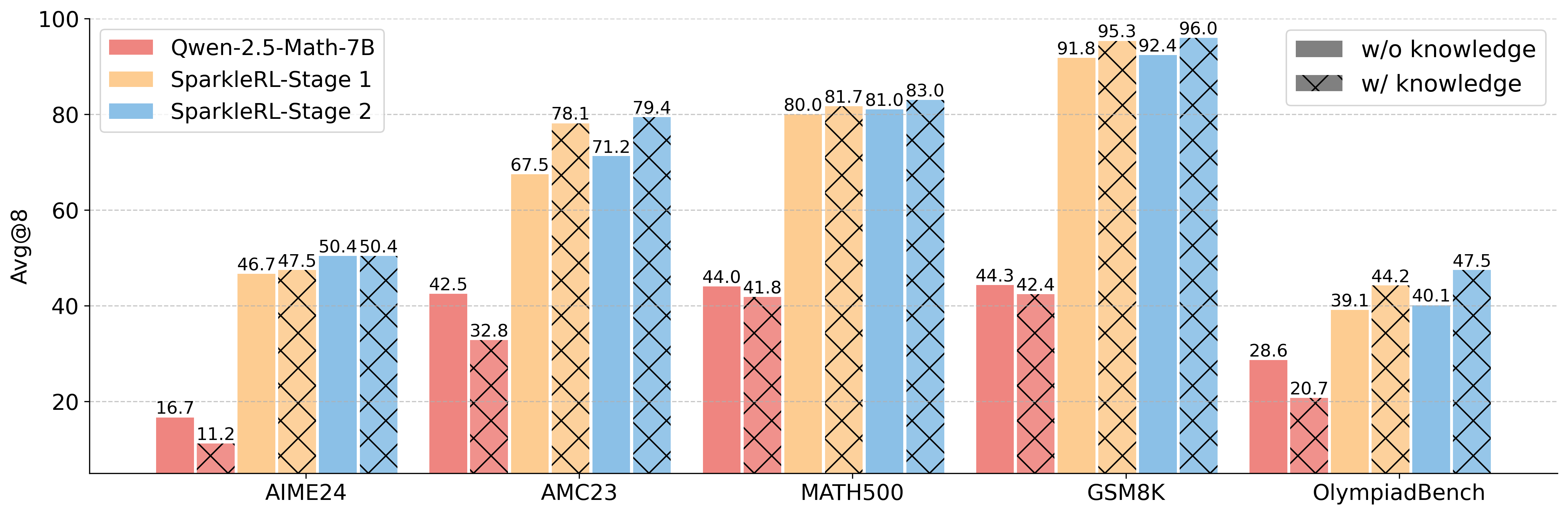
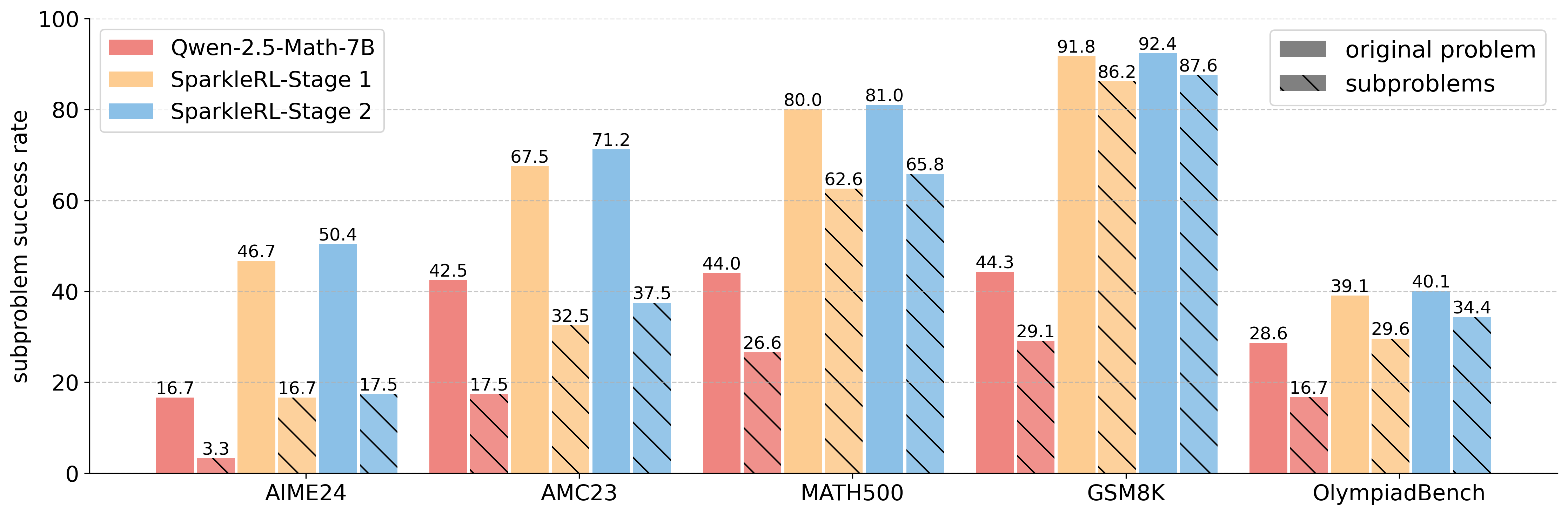
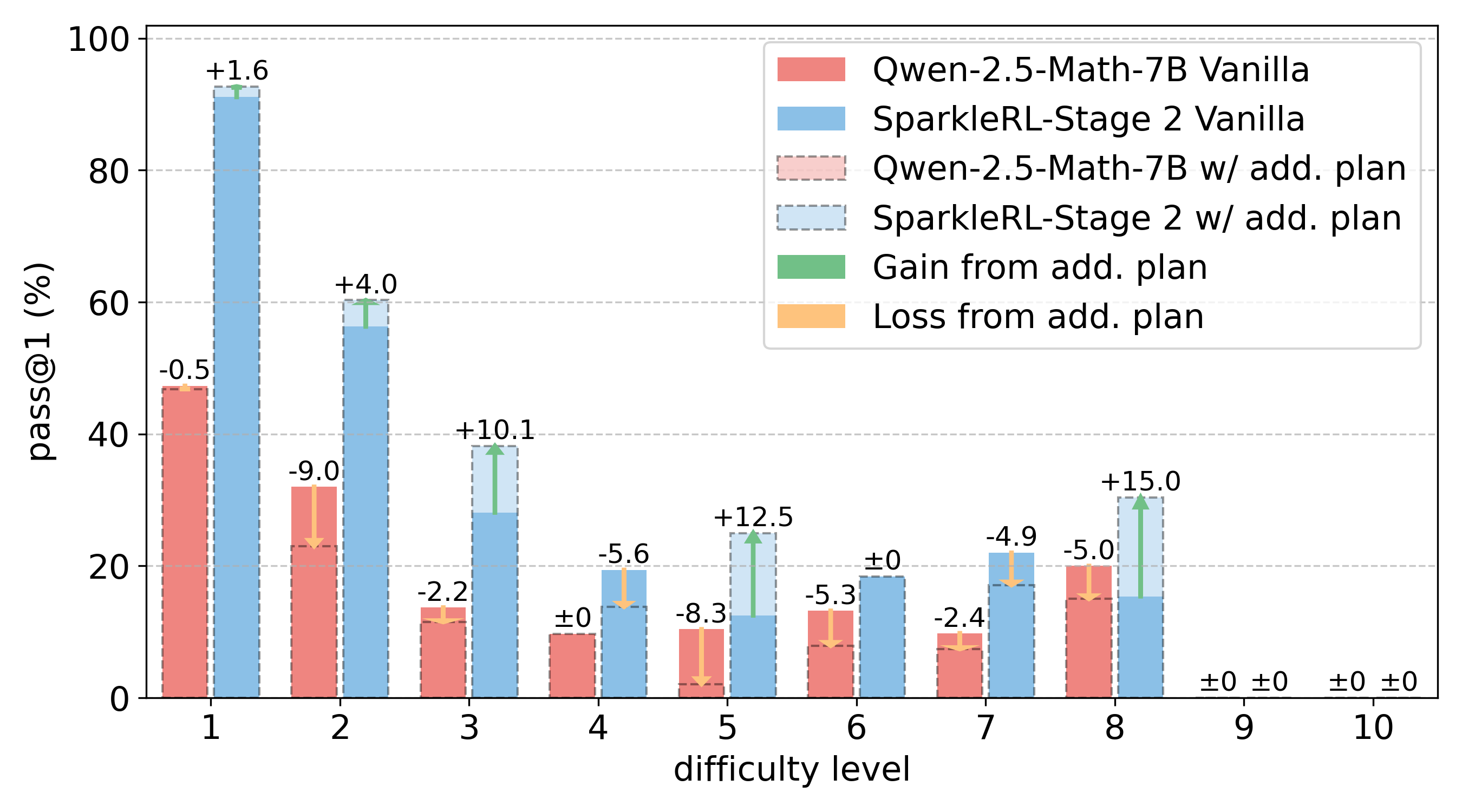
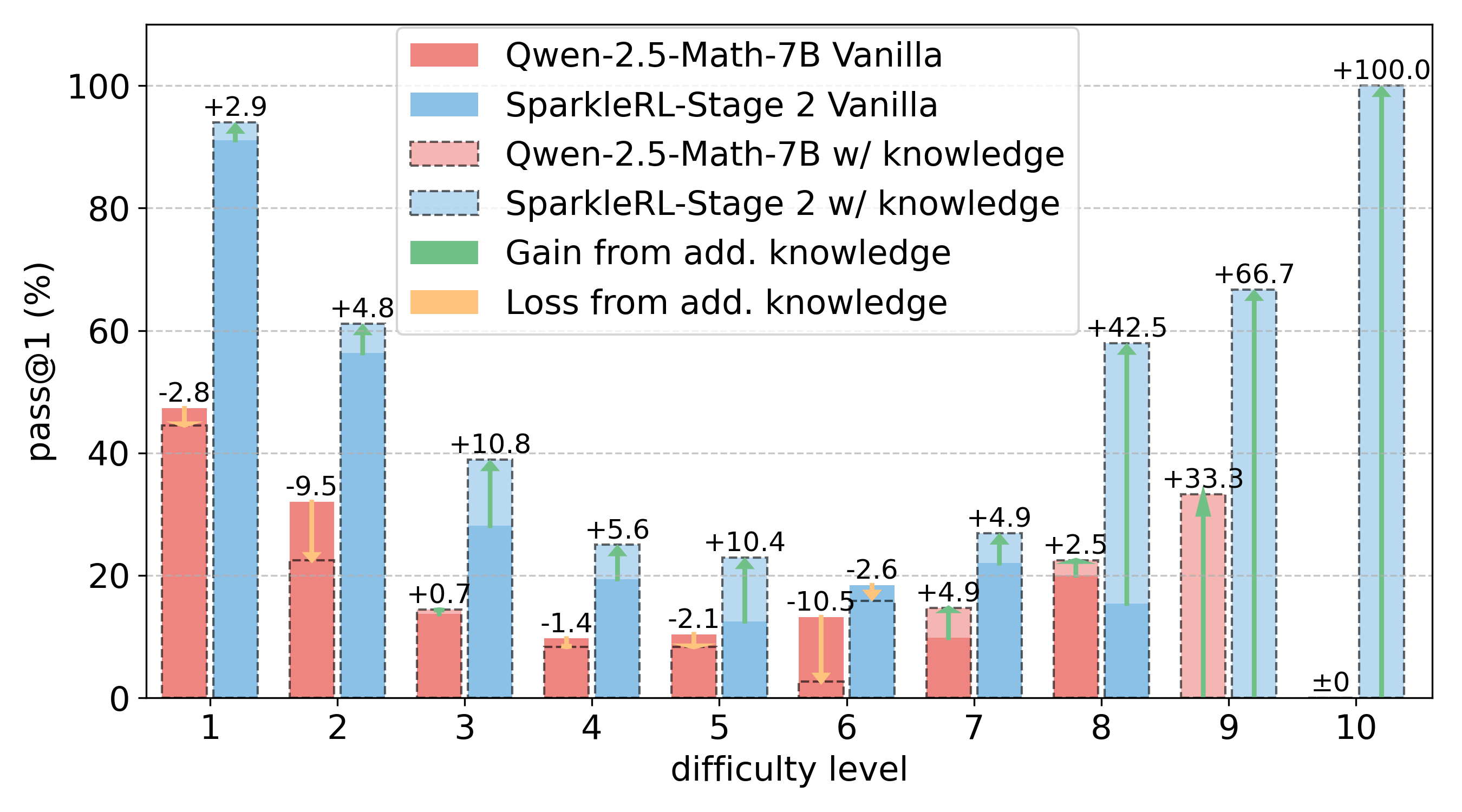
Reinforcement learning (RL) has become the dominant paradigm for endowing language models with advanced reasoning capabilities. Despite the substantial empirical gains demonstrated by RL-based training methods like GRPO, a granular understanding of their advantages is still lacking. To address this gap, we introduce a fine-grained analytic framework to dissect the impact of RL on reasoning. Our framework specifically investigates key elements that have been hypothesized to benefit from RL training: (1) plan-following and execution, (2) problem decomposition, and (3) improved reasoning and knowledge utilization. Using this framework, we gain insights beyond mere accuracy. For instance, providing models with explicit step-by-step plans surprisingly degrades performance on the most challenging benchmarks, yet RL-tuned models exhibit greater robustness, experiencing markedly smaller performance drops than their base counterparts. This suggests that RL may not primarily enhance the execution of external plans but rather empower models to formulate and follow internal strategies better suited to their reasoning processes. Conversely, we observe that RL enhances the model's capacity to integrate provided knowledge into its reasoning process, leading to performance improvements across diverse tasks. We also study difficulty, showing improved training by developing new ways to exploit hard problems. Our findings lay a foundation for more principled training and evaluation of reasoning models.
 Beyond Accuracy: Dissecting Mathematical Reasoning for LLMs Under Reinforcement Learning
Beyond Accuracy: Dissecting Mathematical Reasoning for LLMs Under Reinforcement Learning